A Comprehensive Evaluation of Claude Code Security Review Capabilities
Author: Juhie Chandra

Executive Summary
AI code security review is often misjudged. Tools scanning pull requests for vulnerabilities, while easy to integrate, are typically evaluated on detection accuracy (e.g., catching SQL injection). Disappointment often leads to the conclusion that models lack capability.
However, this ignores a structural flaw: the lack of codebase-level understanding. Without knowing file relationships, data flow, and risk-carrying components, AI operates on code fragments, missing the system context vital for effective vulnerability detection.
This article details a rigorous, multi-phase evaluation of Claude Code's security review, covering: benchmarking its native /security-review, testing AST context improvement, and designing custom tooling to address these structural gaps.
What Claude Code's security review gets right
Catches prominent, well-documented vulnerability classes (OWASP Top 10) with reasonable confidence
Understands security context well enough to avoid flagging intentionally vulnerable training applications as production issues
PR-level review workflow integrates cleanly into CI/CD pipelines via GitHub CLI
When scoped to single-file, high-confidence findings, it provides genuine signal to developers
Structured JSON output format enables downstream automation and integration
What still requires augmentation
Inter-file data flow analysis and cross-boundary vulnerability detection (e.g., path traversal across modules)
Coverage of lesser-known CVEs and non-prominent vulnerability patterns
Handling of large codebases without prompt-length failures
Lack of payload generation for testing and validating identified vulnerabilities
Inefficient navigation and understanding of wide variety of vulnerabilities
What we built to address the gaps
A custom Claude Code plugin (/security-review-seezo) combining structured skills and an orchestrated multi-phase workflow that treats codebase understanding as a first-class concern before vulnerability reasoning begins.
Why AI-Assisted Code Security Review Struggles in Practice
Most AI-driven security review efforts fail for a predictable structural reason. They attempt to move directly from a code diff to a list of vulnerabilities.
A common assumption is that the problem can be solved by providing more input. Teams pass entire codebases, AST graphs, architecture documentation, and custom prompt instructions into a model and expect better security findings to emerge. The issue is the absence of a coherent, security-review-ready codebase representation. Code diffs are fragments. A pull request shows what changed, not what the change connects to. Two files might share a data flow path that creates a path traversal vulnerability, but if the model only sees the diff for one file, that relationship is invisible.
Experienced security engineers recognize this immediately. In real code review, most of the effort is not spent identifying individual vulnerable lines. It is spent understanding how data moves through the system: which inputs reach which sinks, which boundaries are enforced, which configurations are active, and what the dependency graph looks like. Senior security engineers often spend more time building a mental model of the codebase than they do cataloguing specific vulnerabilities.
When AI is asked to generate a security review directly from a diff or raw codebase, it is effectively being asked to perform three tasks simultaneously:
Infer how the codebase is organized
Decide which areas carry security risk
Reason about specific vulnerabilities
This is where AI-generated security reviews typically fail. The output looks generic because the codebase was never sufficiently legible to support meaningful reasoning. Before vulnerability reasoning begins, the codebase needs to be decomposed into identifiable components, data flows need to be traced, and risk boundaries need to be stated rather than implied.
1: Benchmarking Claude Code's Native Security Review
The first phase of our evaluation was straightforward: measure what Claude Code's built-in /security-review command actually catches, and what it misses.
Methodology
We tested Claude Code against multiple intentionally vulnerable codebases, each representing different technology stacks and vulnerability classes:
Dataset | Technology Stack | Purpose |
OWASP Juice Shop | Node.js / Express / Angular | Modern web app with business logic and technical vulnerabilities |
djangonV | Django / Python | Django application with multiple vulnerability types |
PyGoat | Django / Python | Educational – intentionally vulnerable training application |
DiverseVul | C / C++ (real-world samples) | Isolated vulnerability samples from GnuTLS, PHP, BusyBox, QEMU |
Claude Code successfully identified common vulnerabilities (SQLi, NoSQLi, XSS, SSRF, IDOR, CSRF, insecure deserialization) in established test environments like OWASP Juice Shop and djangonV, demonstrating competence with standard OWASP Top 10 patterns when the code was directly visible.
However, its limitations surfaced in multiple areas:
Weak Coverage of Lesser-Known Issues: It identified only one out of ten distinct real-world vulnerability samples from the DiverseVul dataset (from projects like GnuTLS, QEMU, etc.), often classifying them as educational or intentional.
Limited CVE Knowledge: Detection was restricted to prominent patterns, missing subtler issues, particularly unsafe memory operations in C/C++ and protocol flaws.
These hard exclusions are hardcoded in the codebase in a prompt.
Hard Exclusions (to reduce false positives)
Denial of Service (DoS) vulnerabilities, even if they allow service disruption
Secrets or sensitive data stored on disk (handled by other processes)
Rate limiting or resource exhaustion issues
Memory consumption or CPU exhaustion issues
Lack of input validation on non-security-critical fields where there is no proven exploitation path
Master Prompt Architecture for Claude Code /security-review
Phase 1 – Repository Context Research: Using file search tools, the model identifies existing security frameworks, established secure coding patterns, sanitization/validation patterns, and the project’s security model.
Phase 2 – Comparative Analysis: Compares new code changes against existing security patterns, identifies deviations from established secure practices, flags inconsistent implementations, and notes new attack surfaces.
Phase 3 – Vulnerability Assessment: Examines each modified file for security implications, traces data flow from user inputs to sensitive operations, checks for unsafe privilege boundary crossings, and identifies injection points and unsafe deserialization.
Community Perspective
These findings align with external evaluations. Semgrep's analysis found that Claude Code identified 46 real vulnerabilities across 11 applications, yielding a 14% true positive rate. Checkmarx researchers observed that the tool misses moderately complex vulnerabilities and can be influenced by code-level misdirection to overlook genuine issues. The consensus across security practitioners is consistent: Claude Code is a useful supplementary layer, not a replacement for SAST, DAST, or human review.
2: Does AST Context Improve Detection?
A natural hypothesis was that Claude Code's limitations stem from insufficient structural context. If the model cannot see how files relate, perhaps providing Abstract Syntax Tree data, function call graphs, and inter-file dependency information would improve its detection capabilities.
Experimental Design
We used a RAG (Retrieval-Augmented Generation) application codebase as the test target and created ten pull requests, each introducing a single known vulnerability. We then ran two categories of scans.
Three Scan Types
Scan Type | Description | Methodology |
Scan A: Baseline | Standard security review on PRs | Run security review normally on each PR. Repeat 3 times and compare results |
Scan B: Targeted + AST | Vulnerable feature with extra context | Put code files + their AST graphs in 1 PR and scan |
Results
The findings were unambiguous: AST context did not improve vulnerability detection coverage. Across all scan variations, the model's detection remained effectively the same. Even when AST data was explicitly provided and the custom prompt directed the model to use it for inter-file analysis, the analysis summaries did not reference cross-file relationships.
Vulnerabilities like path traversal, which inherently involve data flowing across file boundaries, were not identified even when the relevant AST context was present.
Why AST Context Failed
Several factors explain this outcome:
The model processes AST data as flat text, not as a navigable relational structure representing code relationships
Even with explicit instructions, the structured graph data is treated as additional context rather than a queryable representation
The model’s analysis remained file-local; it did not synthesize AST information into cross-boundary vulnerability reasoning
Prompt-length ceilings meant full-codebase analysis was not just suboptimal but impossible for repositories of even moderate size
Cost and operational constraints made repeated full-context scanning impractical at scale
3: Building Tooling That Changes the Shape of the Problem
The findings from 1 and 2 pointed to a clear conclusion: Claude Code's limitations are not primarily about model capability. They are about workflow design. The model is being asked to perform codebase understanding, risk identification, vulnerability detection, and false positive filtering simultaneously, from a single prompt.
Architecture: The /security-review-seezo Plugin
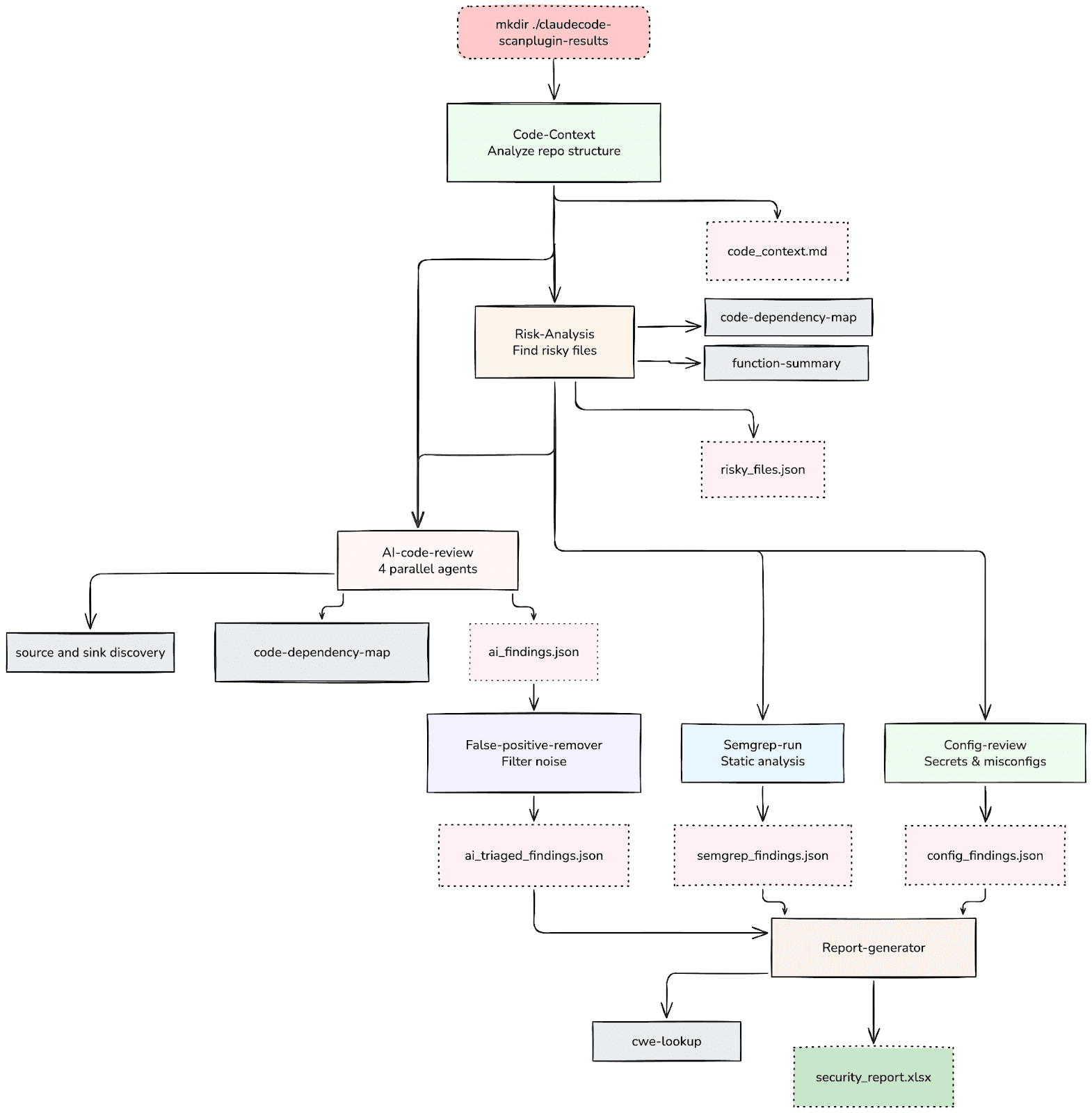
Rather than building an agent from scratch, we built around Claude Code's existing infrastructure using its plugin, skills, and MCP server capabilities. The plugin bundles eleven distinct skills, each responsible for a specific phase of the security review workflow.
Skills Inventory
# | Skill Name | Type | What It Does |
0 | code-context | Skill | Understand how the code is organized and what tools it uses |
1 | risk-analysis | Skill | Find files that might have security problems or valuable areas w.r.t. product context |
2 | config-review | Skill | Check settings files for passwords and wrong settings |
3 | source and sink discovery | Skill | Follow data from where it’s used to where it comes from |
4 | code-dependency-map | Skill | Show how code parts connect and make graphs of risky functions |
5 | semgrep-run | Skill | Check code automatically using the Semgrep tool |
6 | cwe-lookup | Skill | Label security problems with standard names (CWE IDs) |
7 | function-summary | Skill | Describe what functions do and their risks |
8 | ai-code-review | Skill | AI checks code for security problems (4 parallel agents) |
9 | false-positive-remover | Skill | Remove fake warnings and mistakes |
10 | report-generator | Skill | Create Excel report with all findings |
Sub skills:
Source and sink discovery Analysis (source and sink discovery): Traces data flow from dangerous operations (database queries, system calls, file operations) backward to their input sources, identifying unsanitized paths.
Code Dependency Mapping (code-dependency-map): Builds graphs showing how code components connect and identifies functions with high blast radius.
Function Summary (function-summary): Generates structured summaries of what each function accepts, returns, and does, creating a navigable map of behavior.
The design separates the review into discrete, ordered phases:
Phase 0 :- Code Context (code-context): Before any security analysis begins, the plugin analyzes the repository structure, identifies the technology stack, maps frameworks and libraries, and produces a structured code_context.md file. The goal is not insight yet, but shared understanding of what exists.
Phase 1 :- Risk Analysis (risk-analysis): Using the code context, this skill identifies high-risk files, areas where security-sensitive operations concentrate, entry points, authentication boundaries, and data handling patterns. The output is a risky_files.json that focuses subsequent analysis on the areas that matter most.
Phase 2 :- Structural Analysis (sequential or parallel execution): Multiple skills run to build a richer picture of the codebase's security surface:
Config Review (config-review): Checks settings files, environment configurations, and infrastructure definitions for secrets, misconfigurations, and insecure defaults.
Semgrep Integration (semgrep-run): Runs Semgrep static analysis against the identified risky files, producing structured findings that complement the AI analysis.
AI Code Review (ai-code-review): With all structural context assembled, four parallel AI review agents analyze the codebase. Unlike the native /security-review, these agents operate with full access to the code context, dependency maps, source and sink discovery traces, and function summaries generated in prior phases. This is where the model's reasoning capability is most effectively applied, because the codebase is now legible.
Phase 4 :- False Positive Removal (false-positive-remover): A dedicated filtering step evaluates each finding against the structural context, removing findings that are protected by existing security patterns, mitigated by framework defaults, or otherwise not exploitable in context.
Phase 5 :- CWE Enrichment and Reporting: Findings are labeled with CWE identifiers (cwe-lookup), and a consolidated Excel report (report-generator) is produced with separate sheets by severity level and a summary dashboard.
Skills as Interfaces
Each skill in the plugin operates with explicit input and output contracts. The code-context skill produces a structured markdown file. The risk-analysis skill consumes that file and produces JSON. The AI review agents consume all prior outputs and produce structured findings.
The function-summary skill draws from academic work on code summarization (ACM DL: doi.org/10.1145/3728912). Given the source code of a function, it generates a structured summary in the format:
Function Summary Format input:<INPUTS> | output:<OUTPUTS> | behavior:<BEHAVIOR1>, <BEHAVIOR2>, ... where <INPUTS> lists the parameters the function accepts, <OUTPUTS> lists the return values, and <BEHAVIOR> concisely describes the function’s behavior in conjunction with input and output variables, without any other details other than the operations performed. |
Early Results
The application scan provided a detailed security posture overview. Key outcomes included:
Application Architecture Mapping: A code_context.md file was generated to map the application's architecture.
High-Risk Files Identified: 40 files were flagged as high-risk.
Static Analysis Findings: 10 findings were produced by Semgrep.
Secrets and Misconfigurations: 15 secrets and 13 misconfigurations were found during the config review.
AI Code Review: 20 findings were initially generated by the AI code review.
Validated Findings: After a false positive removal process, 5 high-priority, validated findings were retained for remediation.
The entire pipeline, from initiation to final validated findings, completed in approximately four minutes.
The PR Review Extension
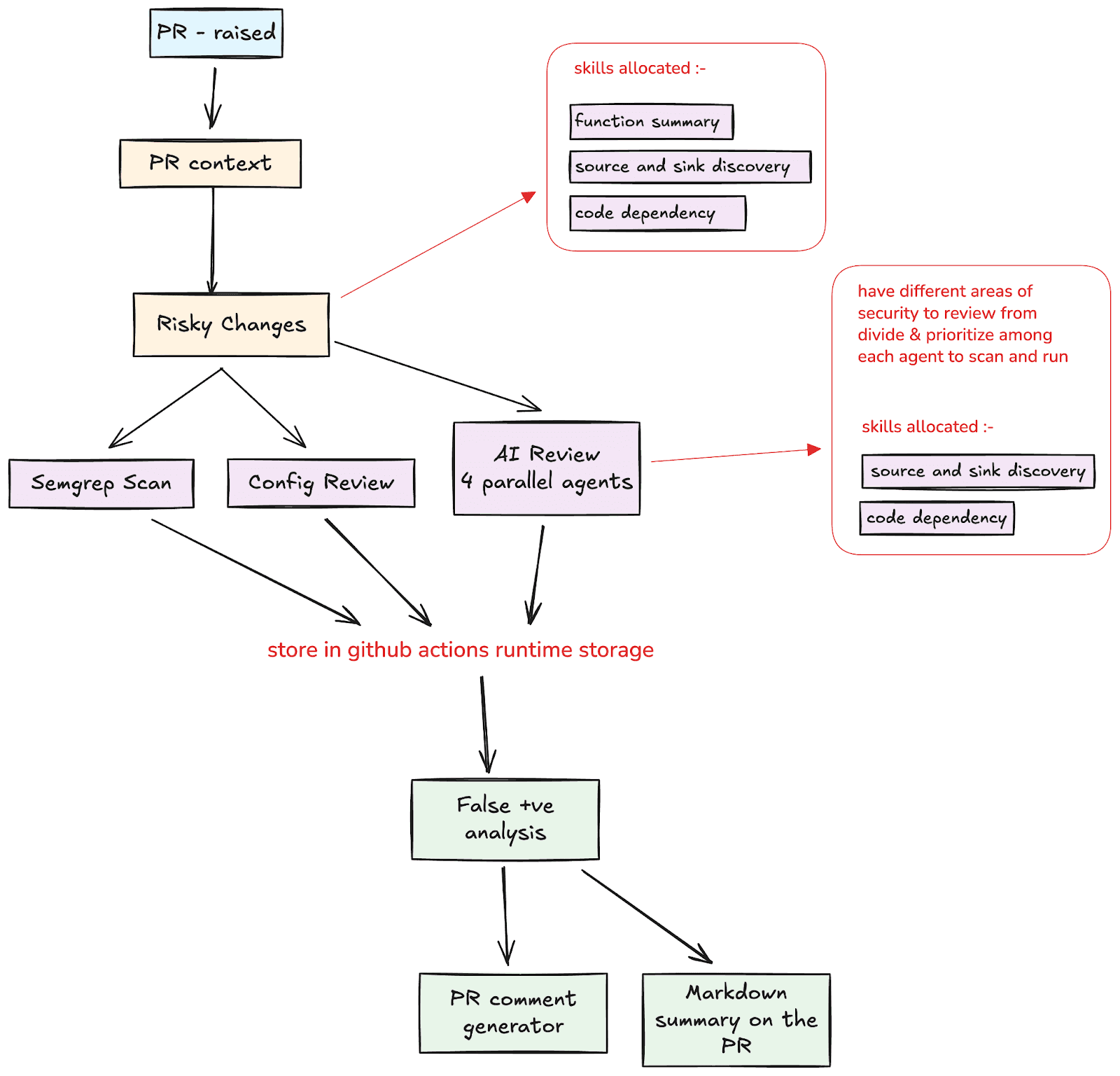
While the initial plugin targets complete codebase review, the architecture extends naturally to PR-level review. The workflow adapts by starting from the git diff, generating function summaries for changed code, mapping the blast radius of changes through the dependency graph, and then running the same parallel analysis pipeline (source and sink discovery, vulnerability pattern analysis, config checks) scoped to the changed code and its immediate dependencies. False positive filtering and CWE enrichment follow the same path.
This addresses the fundamental limitation identified in Approach 2 (AST): PR review fails not because the model cannot reason about individual files, but because it cannot see the surrounding context. The tooling makes that context explicit before review begins.
What This Approach Does, and Does Not Change
The custom tooling does not attempt to automate security review end to end. It mechanizes only the parts of a senior security engineer's workflow that are structured, repeatable, and context-heavy, while deliberately preserving the model's strength in pattern recognition and natural language reasoning about code behavior.
AI is used to normalize fragmented codebase information into a coherent structural representation, decompose repositories into risk-ranked components, trace data flows from sources to sinks, enumerate vulnerability candidates once context is clear, and apply standard taxonomies to produce structured, inspectable outputs. It prepares the ground for reasoning, then applies reasoning within a bounded scope.
What AI does not do is decide which findings matter most in a business context, resolve ambiguity about whether a pattern is intentional or accidental, accept or reject risk, or claim completeness. Those responsibilities remain human. The tooling enforces this by design: it produces findings and classifications, not decisions.
The practical effect is that security engineers spend less time on the mechanical work of understanding how a codebase is organized and more time on the judgment-driven work of evaluating whether a finding represents real risk. Instead of debating whether the model missed something obvious, reviews focus on assumptions, trade-offs, and edge cases.
Note: The orchestration workflow remains adjustable and expandable. In future, adding a skill for taking business context could help resolve this.
Implications for AppSec Teams
First, codebase understanding matters more:- Across all three approaches, the quality of security findings correlated more strongly with how well the codebase was represented to the model than with prompt engineering or additional context injection. A phased approach that builds structural understanding before vulnerability analysis consistently outperformed single-pass approaches, regardless of how much raw data was provided.
Second, the native Claude Code /security-review is useful but bounded:- It catches prominent vulnerability classes with reasonable confidence and integrates well into CI/CD workflows. Its 14% true positive rate (per Semgrep’s analysis) is meaningful: if it catches even a few real vulnerabilities per sprint that would otherwise reach production, the value is clear. But relying on it for coverage guarantees would be a mistake.
Third, AST context alone does not solve the inter-file analysis problem:- Providing more data in the same workflow does not change the fundamental constraint. The model processes AST graphs as text, not as navigable structures. Effective use of structural data requires tooling that decomposes the data into specific, bounded questions.
Fourth, phased analysis with explicit intermediate outputs is more reliable than monolithic generation:- Each phase produces an inspectable artifact: a code context document, a risk ranking, a dependency map, a set of findings. This makes the review auditable and debuggable. When a finding is wrong, you can trace which phase introduced the error.
Fifth, integration with deterministic tools like Semgrep is complementary, not redundant:- AI-driven review and rule-based static analysis find different things. Combining them, and using AI to generate new Semgrep rules when high-confidence novel patterns are identified, creates a feedback loop that improves both approaches over time.
Closing Perspective
When code security review becomes cheaper to initiate and easier to structure, teams can do it more often, focus human attention on what is genuinely ambiguous rather than what is mechanically detectable, and escalate only when the risk justifies deeper analysis. That is how mature security programs scale without exhausting their engineering teams.
In practice, AI-assisted code security review does not fail to scale because models cannot identify vulnerabilities. It fails because codebase understanding and cross-boundary reasoning require structural context that does not fit into a single prompt.
The progression from Approach 1 through Approach 3 demonstrates this clearly. Claude Code’s native review catches what it can see. Providing more raw context does not help it see more. But restructuring the workflow so that the codebase is understood before vulnerabilities are assessed, and so that each phase of analysis operates within a bounded, well-defined scope, produces meaningfully better results.