Seezo Is Even Better Than Before. And It’s All In the Components
|
Thought Leadership
Even with happy customers and a stable platform, we chose to rebuild our architecture from the ground up. This post breaks down why we did it, what changed, and what it means for AppSec teams today.

A few months ago, we made a decision that, on the surface, doesn't make a lot of sense. We had paying customers. They were happy. The platform was stable… And then we decided to rebuild the architecture. This post is about what we changed, why we changed it, and what it means if you're running an AppSec program today.
Building for What Comes Next
Here's how Seezo used to work: You'd give us a design document, an architecture spec, a system design, whatever your team produces before writing code. We'd analyze the document and generate security requirements: Is the database encrypted? Are the APIs authenticated? Are there input validation gaps?
But we knew where the platform needed to evolve, and we chose to move deliberately while it was stable, customers were satisfied, and we had the room to build thoughtfully.
Component-level detail could appear in the earlier results. The models would sometimes call out which database or which service was affected. But it wasn't consistent, and it wasn't something we could build on. If you want to track a component's security posture across multiple assessments, or map findings to actual code, or build an organization-wide picture of your architecture, you need the system to know what the components are every time.
That's what we set out to change.
Internally, we've always been clear that the Seezo of 2025 is step one of a three-step journey. Step two is code integration. Connecting our security analysis to what's actually in the codebase, not just what's in the design document. Step three is what we call Spaces: persistent, company-wide context environments where every assessment your organization runs adds to an evolving understanding of your architecture. Components, assets, and data flows, accumulated over time across applications and teams. A real picture of your security posture at the organizational level, not just assessment by assessment.
Those have always been the targets. Without component-level specificity, code integration will be inaccurate. You can't map code to an architecture if you don't know its components. Spaces are impossible too. You can't build a company-wide component view if your system doesn't think in components. Every future milestone we cared about required the system to understand what it was looking at, not just read what it was given.
So we made the call to make a change despite business being good, the market being as active as it’s ever been, and even while enterprises were onboarding. Our new component-first approach starts from a different premise. Before we do any security analysis at all, we break the design document down into its constituent parts.
Components. Assets. Data flows.
If a design document describes three microservices talking to two databases through an API gateway, our new component-first approach identifies each of those as distinct components. It maps the assets — what data lives where, what's sensitive, what's user-facing. It traces data flows between components: this service writes to that database, this API accepts input from that client, this queue passes messages between these two services.
What you get is a structured representation of the system described in the document. A list of components, a list of assets, a map of how they connect. We think of this as a context graph.
Only after we have this component-level map do we start asking security questions. And now, when we ask "is the database encrypted?", the answer isn't a single yes or no. It's: Database A is encrypted. Database B is not. Database C doesn't have enough information in the design document to determine.
Every security requirement now traces back to a specific component. You can see which component triggered it, what data flows through it, and why we flagged it.
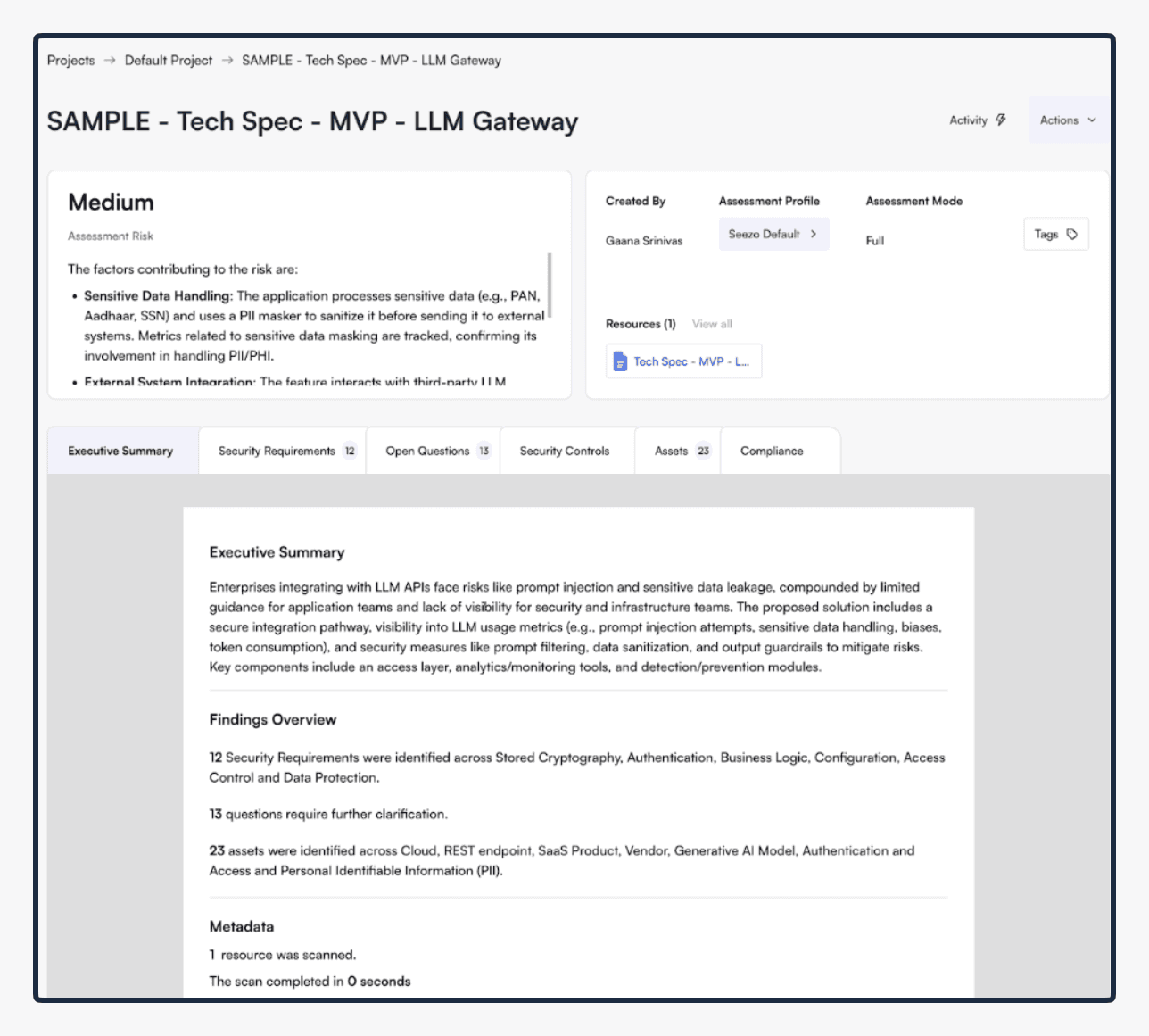
Executive summary before the product upgrade
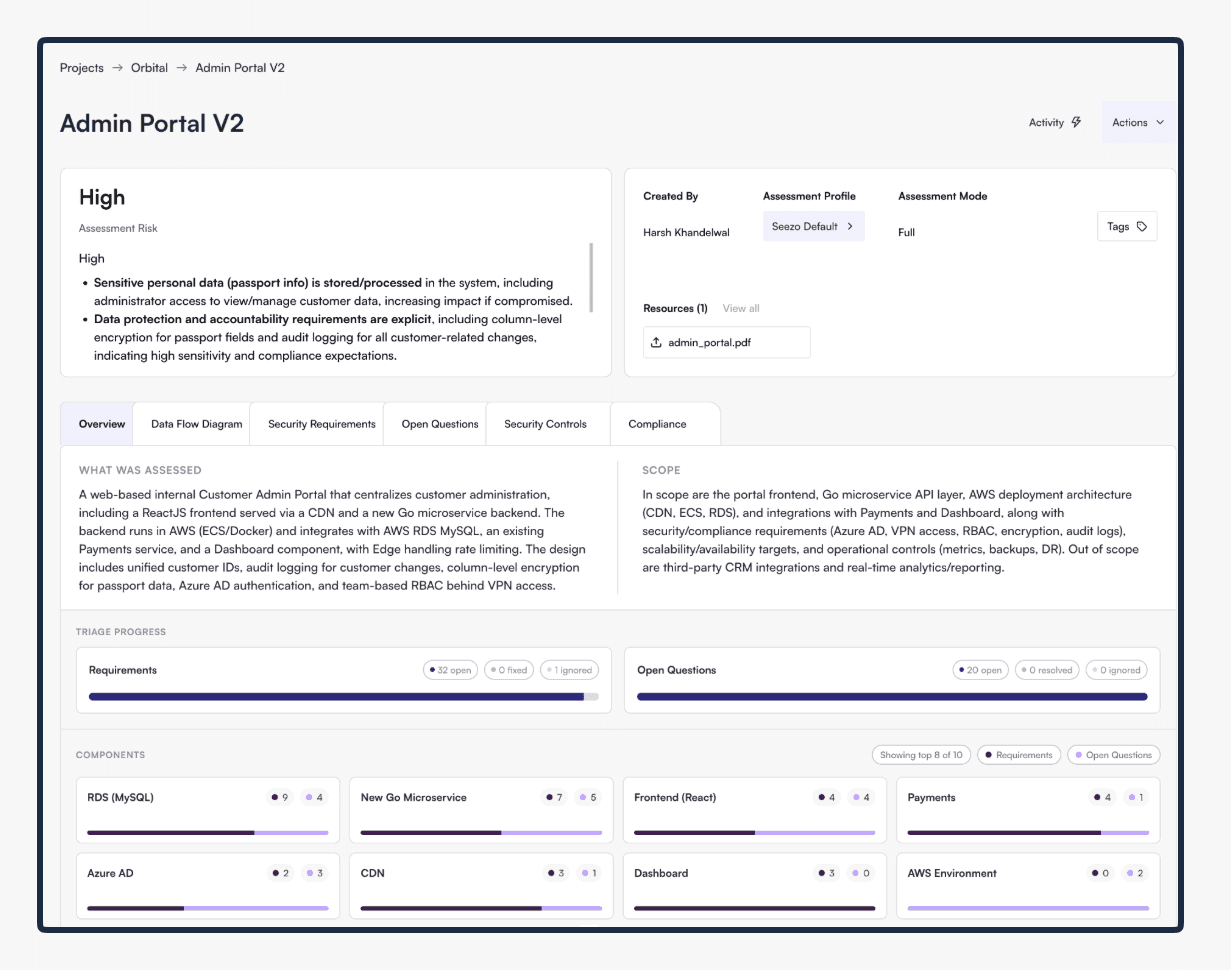
Executive summary after the product upgrade
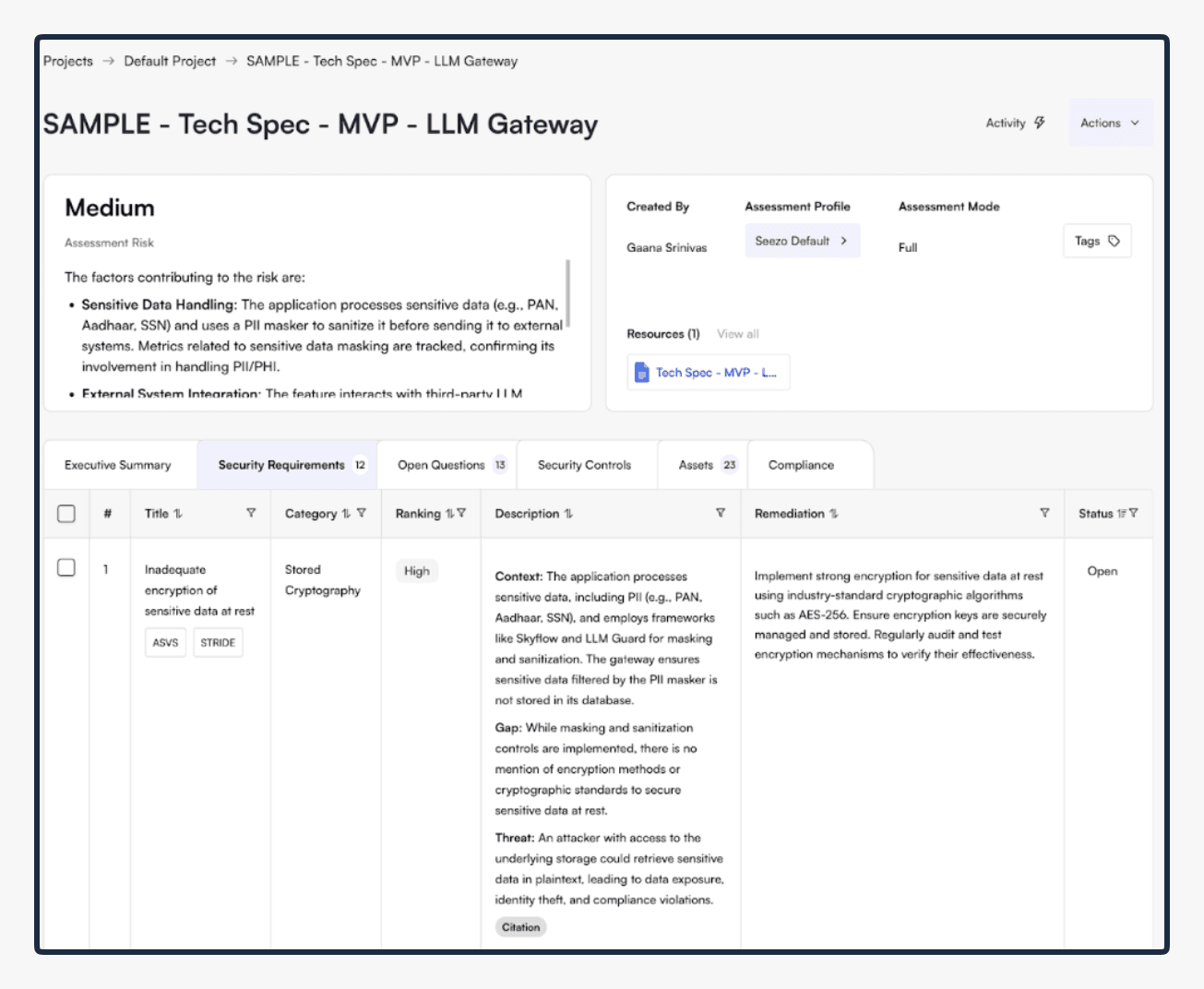
Security Requirements before product upgrade

Security Requirements after product upgrade
Turns Out, You Still Need the Picture
When we started Seezo, I had a specific view on Data Flow Diagrams. I'd written about it publicly in Edition 31 of Boring AppSec last October, I argued that diagramming, while useful, was not a mandatory step in modern security design reviews. LLMs could go straight from unstructured design documents to security requirements without needing the intermediate artifact of a diagram.
I wasn't wrong about the technical capability. You can skip the diagram. But after about a hundred customer conversations — myself, Rakshita, and Kabir talking to CISOs, AppSec leads, security architects at RSA last year, in direct sales calls, in design reviews with enterprise teams — we realized something more nuanced.
An LLM doesn't need a visual diagram to reason about data flows. But we’re building a system where agents and humans need to work together. And they think differently.
Agents need a structured, machine-readable context to operate on. The kind of data you can query and reason over programmatically.
Humans need something they can look at, challenge, and trust. A diagram. A visual representation where you can point at a component and say, "That's wrong, the data doesn't flow that way."
What we realized is that you need a representation layer that serves both simultaneously. The component model gives agents what they need. The DFD gives humans what they need. And they're generated from the same underlying data, so they stay in sync.
That said, not all DFDs are equal. It's straightforward to generate something technically correct but ugly and unusable. What we're proud of is that ours is interactive, contextual, and beautiful. Each node is explorable, each connection is traceable, and there is a layer of rich metadata built into our new DFD that is intuitive to summon and process.
The old diagramming tools, such as Microsoft's Threat Modeling Tool, and others with proprietary interfaces, required the DFD as input. You drew the diagram, then the tool analyzed it. We generate the DFD as output, derived from the system's own component analysis. And each component on our diagram carries real information: what it is, what data it handles, how it connects to other components, what its risk profile looks like. The legacy tools gave you a diagram with nothing behind the nodes. We give you a diagram where each node is a window into everything the system knows about that component.
So we ended up somewhere I couldn’t have predicted two years ago. We're generating the artifact that I thought LLMs would make unnecessary. But we're generating it from analysis, not requiring it as a prerequisite. And because it's backed by structured component data, the DFD is actually useful in a way the old hand-drawn versions often weren't.
I don't think of this as a retreat to legacy approaches. It's more that the path from where AppSec teams are today to where they need to be tomorrow requires building something that works at two levels: agent-operable and human-understandable. No gaps between the two.
What This Changes For You
If you're an existing Seezo customer, or if you're evaluating the platform, here's what these improvements mean in practice.
Security requirements are more precise. Because they're generated at the component level, not the document level, each requirement now maps to a specific part of your system. You're not getting a blanket "ensure databases are encrypted." You're getting a requirement tied to a specific database, with context about what data flows into it and why encryption matters for that particular component.
You get a visual DFD. This is generated from the same component analysis that drives the security requirements. You can look at the diagram, see how your system is structured according to the design document, and immediately spot where the security issues are. When you see a requirement you disagree with, you can trace it back to the diagram and understand exactly what the analysis was looking at.
Explainability is structural, not cosmetic. A lot of AI-enabled products bolt on "explainability" as a post-hoc justification — the model makes a decision, and then the product generates an explanation for why. Now in Seezo, the explanation is built into the architecture. The component breakdown is the explanation. You can see what components exist, how they relate to each other, what assets are involved, and how the security requirements connect to all of it. If you disagree, you have enough information to make that judgment.
The foundation for what comes next. Here's why the component model matters beyond this release. Once you break a design document into components, something interesting happens when you bring in a second design document. And a third. Components start appearing across multiple documents. That database isn't just used by one application — it shows up in three different design docs across different teams. Now we can start building a picture that spans your entire application portfolio. This is Spaces — persistent, evolving context environments where every assessment adds to the organization's understanding of its own architecture. Code integration becomes possible too, once you have structured components to map code against instead of just scanning files. None of this was possible without the component model. That model is what makes the rest of the roadmap real.
From Carpentry to Gardening
There’s also a broader shift happening, largely thanks to AI, in how AppSec teams work, and our new component-first approach is built for that shift.
As AI takes on more of the analysis work, the AppSec engineer’s job will change in shape. Engineers will spend less time manually running security assessments.
Instead, they will spend that time on three things that only humans can do really well: defining when and how security tools run in your workflows, giving the system the right context — your standards, your secure-by-default patterns, your organizational rules — and supervising results with enough visibility to know when the system got it wrong and why.
The component model makes this much more possible. When every security requirement traces back to a specific component with visible reasoning, AppSec engineers can supervise effectively. This means you're not reviewing a black box output and hoping it’s right. But looking at a structured breakdown of your system and making calls about what to accept, what to challenge, and what context to feed back in.
I wrote about this shift in Edition 33 of Boring AppSec. About how the AppSec role moves from direct execution to strategic oversight, what that means for team structures, and why the engineers who adapt to this model become more valuable, not less.
If you’re thinking about what your AppSec program looks like in two years, it’s worth a read.
Three Approaches Dominate the Market. Seezo Is Taking A Fourth One
I think there are three approaches in the market right now, and none of them are quite right.
The first camp is what I'd call the automagic companies. Give them access to your repos, your cloud, your docs. They'll handle it. No real customization, no explainability to speak of. Their argument: why do you care how we got there? Just look at the output. This gives you power without agency. When something is wrong, you can't trace the reasoning. You can't correct the system's understanding. You're a passenger.
The second camp is legacy tools with AI bolted on. They had structured methodologies. Some had DFDs, some had questionnaire-based approaches. But they weren't automating the analysis. They were giving you software to do manual work faster. Now some have added an LLM layer. The architecture underneath hasn't changed. It's an old product with AI on top.
The third camp is the frontier AI labs. I wrote about this in Edition 32 — Anthropic, OpenAI, AWS, and others are shipping security features. Some of them are impressive. But application security is not their core business. Their models are optimized for general-purpose intelligence, not for the domain-specific context work that AppSec requires. Building a great general-purpose model and building a great AppSec platform are different problems.
What we're building is different from all three. A system where the AI does the heavy lifting, but humans can see what it understood, challenge it, correct it, and control how it operates. Power and agency. The component model, the DFD, the context graph, and the explainability are all designed so that both sides of the equation improve at the same time. The agents get richer context to work with. The humans get better visibility into what the agents are doing.
What It Took to Build This
This was not a simple upgrade.
The core challenge in the earlier version: you upload a document, we run a few thousand security questions against it, and you get results. Straightforward. Now: we first break the document into, say, 10 components, and then run questions against each component. Naively, that's a 10x increase in time and tokens. A document that took 6 minutes to assess would take 60.
That was not acceptable.
The team spent months on optimization. We built a preprocessing step that determines which questions are actually applicable to each component. A database component doesn't need questions about API authentication. We parallelized analysis across components, which required rearchitecting how we orchestrate infrastructure on AWS. And we adopted different models for different tasks.
We now deliberately and thoughtfully use different models for different jobs. One model for identifying components, another for mapping data flows, another for running the actual security analysis. We tested extensively across providers (OpenAI, Anthropic's Claude, Gemini, etc.) and matched model strengths to the specific characteristics of each task. Component identification is a different kind of problem than security rule application. Using the right model for each step made a noticeable difference in both speed and quality.
The result: Our new approach achieves parity with the old one on processing time, sometimes faster. Despite doing significantly deeper analysis. We didn't expect that. We were mentally prepared to tell customers "it's slower but better." The fact that we got back to speed parity while adding the component layer was, honestly, a pleasant surprise.
And we did all of this while keeping the existing platform running for current customers. No downtime, no forced migration. All our customers continue to work exactly as before. Even as we built a new foundation for our product and our user experience.
If You're at RSA
We're going to be at RSA later this month. If anything in this post made you think — whether you agree, disagree, or just want to explore these ideas further — come find us at Booth ESE64.
We're not going to give you a hard sell. What we will do is have an honest conversation about where AppSec is heading in the age of AI, what the real challenges are, and how we're thinking about solving them. If you've been feeling like the discourse around AI and security is either too alarmist or too hand-wavy, you might find the conversation useful.
And if you want to see the shiny new Seezo component-first philosophy in action, we can do that too.
Sandesh Mysore Anand is the co-founder of Seezo and writes the Boring AppSec newsletter.